In Cluster III, the working group "Algorithmic Analytic Approaches" focuses on issues of research transparency with configurational comparative methods (CCMs), including Qualitative Comparative Analysis (QCA). Ultimately, the goal is to produce a Community Transparency Statement that reflects common understandings of transparency within the research community working with CCMs. While I am absolutely sympathetic to the idea of increasing transparency, I believe the perspective that has been taken so far is too narrowly focused on applied users of CCMs. Rather, at least five different groups of actors should be considered: (1) those who develop the software for CCM research, (2) those who use this software, (3) those who teach CCMs (4) journal editors/reviewers of CCM research and (5) publishers of CCM research. Without due attention to the role of each of these five different groups of actors in the research and publishing process, any comprehensive attempt at increasing research transparency to a reasonable standard is unlikely to be successful. Let's consider each actor group in turn.
(1) Without those who develop CCM software, applied researchers could not analyze their data (pen-and-paper procedures are no reasonable option). However, of the seven multi-version software packages for the R environment listed on the COMPASSS software website (cna, SetMethods, QCA3, QCA/QCAGUI, QCAfalsePositive, QCApro, QCAtools), only four, namely cna, QCA3, QCA/QCAGUI and QCApro provide a log file as part of their distribution where minor and major changes in the functionality or infrastructure between consecutive versions of the package are listed. By means of these log files, users can immediately see whether changes that affect procedures or results have been implemented. With all other CCM software, it is not clear what has changed from version to version, which is highly problematic, all the more so if software is not open source as in the case of fs/QCA. Developers of CCM software should therefore ensure that, even if they do not want to make their source code available, changes between versions are sufficiently documented and new versions are appropriately indicated and numbered.
(2) At least as much of the onus of increasing transparency is on users of CCM software. There are at least three issues that need to be addressed in relation to this group of actors: (a) data availability, (b) the provision of replication "scripts", and (c) proper citation.
Data availability
Sometimes, there are restrictions on access to data, but generally, studies for which the data underlying their findings and conclusions have not been made available lose much credibility. However, if data are made available, they should be provided in a suitable format (TXT, CSV, etc.) for purposes of replication, and not as a table in a PDF or DOC/X file as is currently often the case in social science publications.
Replication scripts
I have reviewed quite a number of CCM manuscript submission so far, but only one of them did include a proper replication script as part of the submission. When software users draw on R packages, there is certainly no reason whatsoever for not submitting a replication script along with the manuscript text, and for publishing this script together with the accepted article. Even with graphical software such as fs/QCA or Tosmana, however, is it possible to provide a replication "script", for example, in the form of a description of the sequence of actions that have been taken in operating the software, from the import of the data to the generation of the final solution, and/or a series of screenshots or, even better, a screen video. There are numerous possibilities, some better than others, but all better than no material.
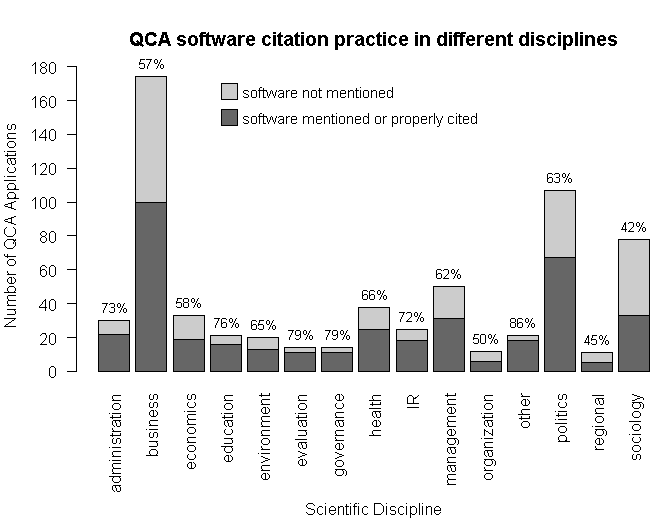
Proper citation
Although one would expect that scientists are conscientious in trying to maintain standards of good scientific publishing, it is surprising to see how rarely users of a particular piece of CCM software cite it. But proper citation is important. It not only acknowledges the work of others that has been used (strictly speaking, everything else is plagiarism), but it also ensures research transparency because different QCA software packages have very different functionality and output very different solutions (see, e.g., Baumgartner and Thiem, 2015; Thiem and Dusa, 2013). The figure below provides an extensive analysis of QCA software citation practices across different disciplines of the social sciences, based on a private data set on QCA publications I have built up over the last five years (885 total) (since I have not made this data set publicly available, you can be skeptical as well, of course).
In the area of business, where most QCA applications have been published by now, not even 60 percent of authors at least mention the software they have used. Political science performs somewhat better with 63 percent, but given the seriousness of the issue, it is still disturbing to see so many applied researchers not acknowledging the work of others that they have used in their own research. The worst performing discipline is sociology, where only 42 percent of authors at least mention the software they have used.
(3) Due to the increasing popularity of methods schools and courses across the social sciences, ever more people teach CCMs to students and researchers at all levels. It should become standard practice for instructors of such courses to integrate the issue of transparency into their teaching. Needless to say, these instructors themselves should also practice what they preach in their own work.
(4) Editors and journal reviewers have an important role to play when it comes to questions of transparency. At least two points require attention. First, and perhaps most easily implementable, journals should require the submission of the data used and suitable replication material so that reviewers get the chance to perform all necessary quality checks on the analysis. The replication script should be provided in a way such that it can be directly read by the respective software. For example, if an R package was used, the replication script should be provided as an R file. The same applies to the data. It makes no sense to provide data sets as tables in a PDF or a DOC/X file, as is still often done, because reviewers and interested readers need to copy or manually re-type these data into an appropriate software for conversion, a process during which many errors may sneak in.
Second, but less easily implementable, if implementable at all anytime soon, the review process itself should be made fully transparent. In other words, (single/double/triple) blind peer review should be abolished because the anonymity of this process produces many scientific distortions, including, for example, the enforcement of inappropriate citations, the suppression of appropriate citations, the unwarranted inclusion or exclusion of theoretical or empirical material, and the misuse of anonymity for influencing private conflicts or otherwise politically instead of scientifically motivated agendas. The full openness of the peer review process would decrease the rate of occurrence of these problems considerably. It would expose all conflicts of interests, it would incentivize reviewers to produce reviews of high scientific quality since their community could evaluate the content of reviews, and it would therefore lead to better science.
(5) In an age of digital publishing, publishers need to provide the necessary infrastructure to help increase transparency. For example, I have only recently managed to make replication files for R available as an online appendix at some SAGE journals. Before, it was apparently technically impossible. The publisher is still having problems, but is seems as if things are gradually improving. Data infrastructure projects such as the Harvard Dataverse software application are laudable attempts at centralizing the open provision of research material, but publishers of scientific literature should improve their direct publication services as well.
References